CMU-MOSEI Dataset

CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) dataset is the largest dataset of multimodal sentiment analysis and emotion recognition to date. The dataset contains more than 23,500 sentence utterance videos from more than 1000 online YouTube speakers. The dataset is gender balanced. All the sentences utterance are randomly chosen from various topics and monologue videos. The videos are transcribed and properly punctuated. The dataset is available for download through CMU Multimodal Data SDK GitHub: https://github.com/CMU-MultiComp-Lab/CMU-MultimodalSDK.
The following table gives an overview of the dataset statistics:
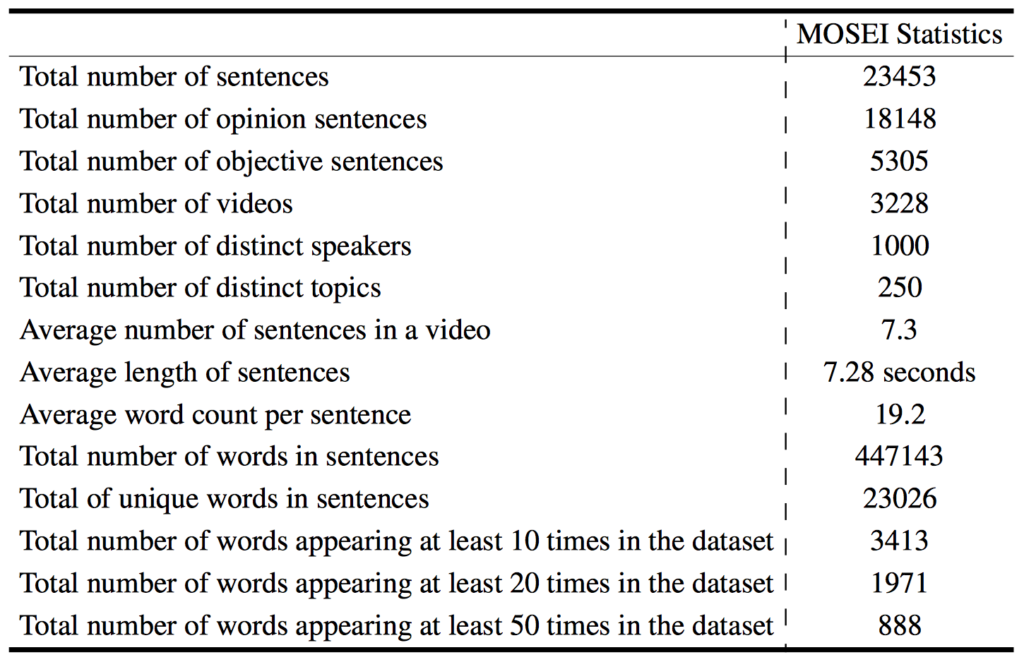
The following table shows a comparison between CMU-MOSEI and other sentiment analysis and emotion recognition datasets:
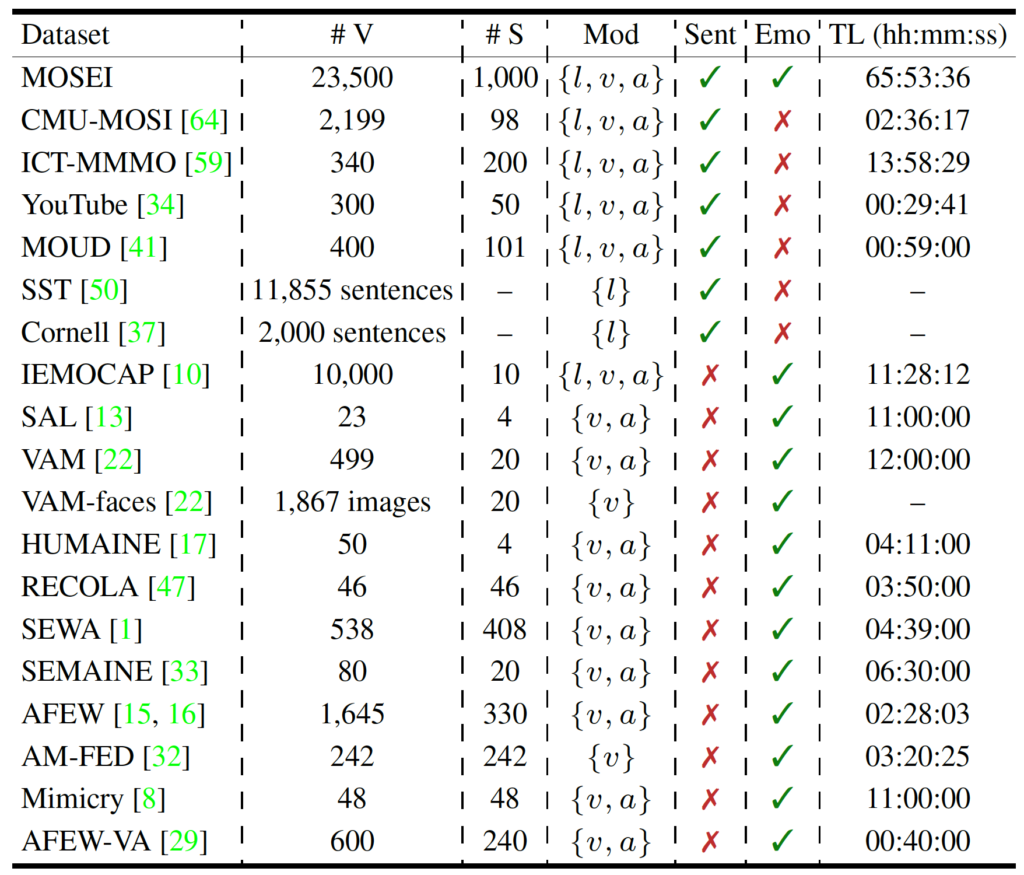
#v denotes the total number of videos, #s denotes the total number of speakers, Mod denotes the present modalities of (l)anguage, (v)isual, and (a)coustic. Sent denotes whether or not the dataset contains sentiment annotations and Emo denotes whether or not the dataset contain emotion annotations. TL is the total length of the dataset.
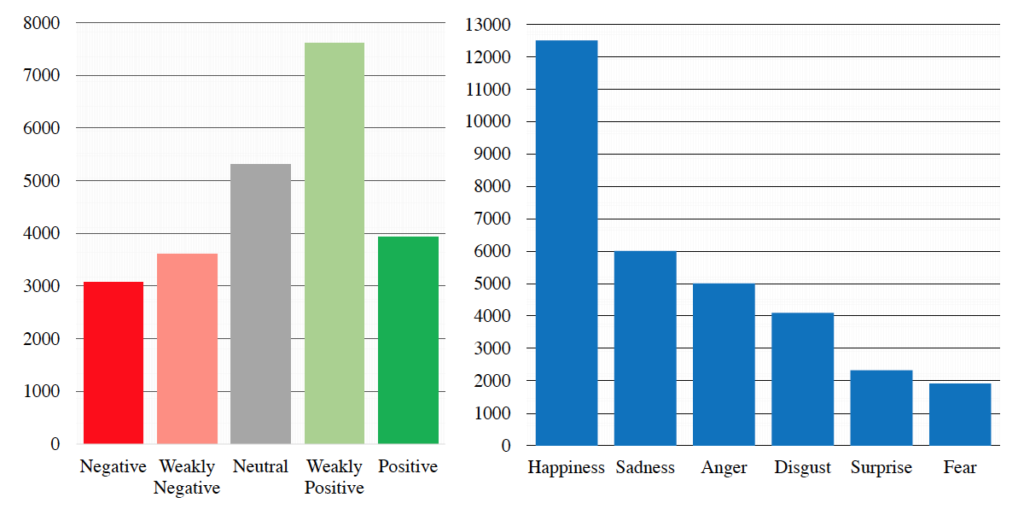
The following figures shows the distribution of sentiment and emotions in the CMU-MOSEI:
The following word cloud demonstrates the topics of the videos (size indicates number of videos):

The dataset is available through CMU Multimodal Data SDK.