Multimodal Graphical Models
In many natural scenarios, data is collected from diverse domains and exhibits heterogeneous properties: each of these domains have different dynamics and present a different view of the same data. Such forms of data are known as multi-view data. In a multi-view setting, each view of the data may contain some knowledge that other views do not have access to. Therefore, multiple views must be employed together in order to describe the data comprehensively and accurately. Multi-view learning has been an active area of machine learning research focused on modeling multi-view data. By exploring the consistency and complementary properties of different views, multi-view learning is considered more effective, more promising, and has better generalization ability than single-view learning.
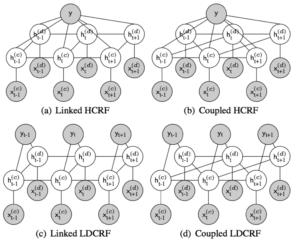
Multi-view sequential learning extends the definition of multi-view learning to manage with different views all in the form of sequential data, i.e. data that comes in the form of sequences. For example, a video clip of a speech can be partitioned into three sequential views — text of the speech, video of the speaker, and tone of the speaker’s voice. In multi-view sequential learning, two main forms of interactions exist. The first form is called view-specific interactions; interactions that involve only one view. One example involves learning the sentiment of a sentence based only on the sequence of words in that sentence. More importantly, the second form of interactions are defined across different views. These are known as cross-view interactions. Cross-view interactions span across different views and times — some examples include a listener’s backchannel response or the delayed rumble of distant lightning in the video and audio views. Modeling these view-specific and cross-view interactions lies at the core of multi-view sequential learning.